人工智能(artificial intelligence)[1],按照維基百科定義,指由人工制造出來的系統所表現出來的智能。這里的人工制造的系統,具體到安防領域,指的就是智能算法。其實現在安防領域中的大多數設備,比如支持移動偵測的IPC、智能分析服務器、視頻濃縮和視頻摘要服務器、非現場執法設備、卡口型攝像機,等等,都實現著人工智能算法。所以,人工智能應用于安防領域,并不是一個新鮮話題。
人工智能學科主要研究算法的以下幾個方面的能力:演繹(deduction)和推理(reasoning)、知識表示(knowledgerepresentation)、規劃(planning)、學習(learning)、自然語言處理(naturallanguage processing)、運動和控制(motionand manipulation)、感知(perception)、社交智能(social intelligence)、創造力(creativity)、通用智能(generalintelligence)。
人工智能學科主要的研究方法有:控制論和腦模擬(cybernetics and brainsimulation),符號法(symbolic):又含有認知模擬(cognitive simulation)法、基于邏輯(logic-based)法、基于知識(knowledgebased)法、子符號(sub-symbolic)法、統計學(statistical)法、集成方法(Integratingthe approaches)。
人工智能學科主要的工具有:搜索和優化(search and optimization)、邏輯(logic)、不確定推理的概率法(probabilisticmethods for uncertain reasoning)、分類和統計學習法(classifiers and statisticallearning methods)、神經網絡(Neuralnetworks)、深度前饋神經網絡(deepfeedforward neural networks)、深度遞歸神經網絡(deep recurrent neuralnetworks)、控制論(control theory)。
深度學習興起
2012年,多倫多大學Geoff Hinton的兩個博士生Alex Krizhevsky 和IlyaSutskever 在NIPS 上發表論文《ImageNetClassification with Deep ConvolutionalNeural Networks》[2],采用深度卷積網絡算法,在圖片分類競賽ImageNet 中的大規模視覺識別挑戰賽ILSVRC-2010和ILSVRC-2012上(如圖1和圖2所示),圖片分類結果均拿到了第一名,并且相比于傳統的手工特征的最好的算法(SIFT+Fisher Vectors)的分類結果(top-1錯誤率和top 錯誤率)減少近10% !(注圖1和圖2中斜體為最好的手工特征算法結果,粗體為CNN 結果,帶星號的為神經網絡結構經過“預訓練”了的分類結果)要知道,在過去競賽中,使用傳統手工特征的形形色色算法的結果提升幅度從沒有這么高。可想而知,這在計算機視覺(computer vision)領域引起地震。同時也拉開了CNN 在計算機視覺領域以及其他領域大量運用,以及CNN網絡結構快速發展的大幕。
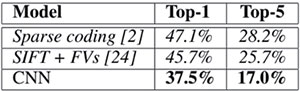
圖1 引文[2]中的ILSVRC-2010中的DCNN和傳統手工特征算法圖片分類結果對比
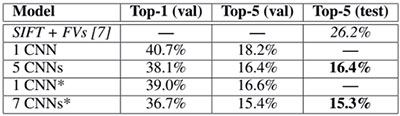
圖2 引文[2]中的ILSVRC-2012中的DCNN和最好的傳統手工特征算法圖片分類結果對比
卷積神經網絡并不是個新鮮算法,在20世紀曾經經歷過一段時期的冷遇,根因是卷積神經網絡訓練過程收斂前需要反復迭代前向傳播和反向傳播,計算量超多,使用現在速度最快的多核CPU 架構,訓練時間也要幾十天。NVIDIA 的GPU 中的數以千計的計算單元陣列的快速發展有效的解決了這一問題,大大縮短了訓練周期。如圖3所示為論文中使用的CNN 訓練結構,該網絡人們習慣上稱為AlexNet。
同時隨著網絡中的連接數(參數)的增多,需要的訓練數據也越多,比如ImageNetLSVRC-2010就含有1000多個種類的120多萬張的圖片。
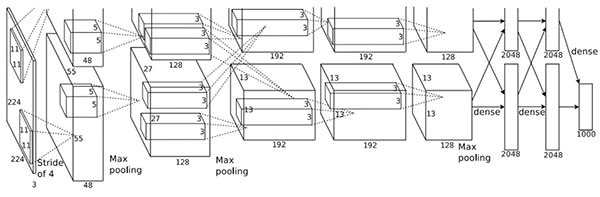
圖3引文[2]使用的由兩個GPU分擔的CNN結構圖
由此可見,GPU 的高速發展以及海量數據的出現,使得深度神經網絡訓練變得可行,加速了深度神經網絡在計算機視覺、語音、文本、自然語言處理等領域的快速普及。
深度學習是機器學習的一個分支。機器學習的目的是根據在訓練數據集上每個樣本的目標值,學習得到一個模型。訓練時,對分類器輸出和目標值進行對比,根據使用的分類器和代價函數(或損失函數,lossfunction),使用優化算法,反復迭代,不斷調整參數,直到算法收斂為止。檢測時使用該模型用于新的樣本,模型的輸出就是我們需要的輸出。如圖4所示。相比于檢測過程(或測試過程),訓練過程需要反復迭代,運算量極大。傳統手工設計特征的表現能力遠遠不及神經網絡的抽象表達能力。這就是神經網絡,尤其是深度神經網絡的優勢所在。
目標值為連續實數時,會學習得到一個回歸器(regressor),目標值為離散值時該機器學習問題為分類。不過有時把回歸和分類問題合在一起訓練。
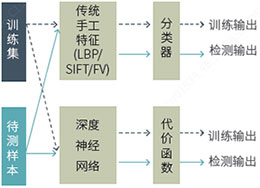
圖4 神經網絡相比手工設計特征具有更強的特征表現力
雖然理論界無法對深度神經網絡如此強大的特征表達能力給出令人信服的理論推導,但是它在實踐應用中的卓越表現極大刺激了它在各個領域的快速推廣。ImageNet 2016 屆大規模視覺識別挑戰賽(ILSVRC-2016)結果剛剛公布,在各個比賽中獲得第一名的團隊采用的算法均是基于深度神經網絡的。
神經網絡結構
神經網絡一般含有輸入層、隱含層、輸出層。
若含有多個或者很多個隱含層,則成為深度神經網絡或者甚深神經網絡,到底多少個隱含層算深,其實在學術界并沒有嚴格的定義。
屬于卷積神經網絡(convolutional neural networks 或CNN)家族的各種結構神經網絡主要用于處理網格結構數據,比如時間序列數據(音頻)可以看成為按照一定時間間隔采樣而成的1D 網格數據;圖像可以看成由像素組成的3D 網格數據;視頻可以看成是由按照時間采樣的2D 圖像組成的3D 網格數據;視頻和光流可以是由2D 圖像加1D 光流按照時間采樣的4D 網格數據;等等。卷積神經網絡主要的操作就是卷積,如圖5 [3] 所示為2D 卷積原理示意圖。卷積操作主要實現了稀疏交互(sparse interactions)、參數共享(parameter sharing)、等變表示(equivariantrepresentations)三種思想。卷積網絡的一個層典型的具有三個階段,首先是執行卷積操作產生一個線性激勵(activation);然后是每個線性激勵執行一個非線性激勵函數,比如校正的線性激勵(rectified linearactivation),這一階段有時稱為檢測(detector)階段;第三階段,使用池化(pooling,或匯聚)操作進一步修改層的輸出,即減少特征映射平面(feature map plane)中特征數目。
在安防領域大量應用的對象檢測、對象跟蹤、對象識別等應用都是基于卷積神經網絡實現。
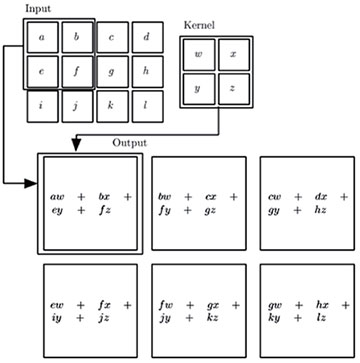
圖5 2D卷積操作示意圖
遞歸神經網絡(Recurrentneural networks/ RNN)家族中各種結構神經網絡主要用于處理序列化數據,所以一般認為遞歸神經網絡對歷史數據具有記憶性,即網絡對當前輸入計算輸出時,既考慮當前的輸入,由考慮歷史輸入。如圖6所示,左邊為未展開的遞歸神經網絡原理示意圖,右邊的為展開(unfold)后的遞歸神經網絡原理示意圖。輸入序列為x,輸出序列為o,y 為目標輸出,L為損失函數,h為內部狀態,W 為網絡連接權值。通過圖6右側看出,網絡內部狀態h 隨著時間發生變化,不同于卷積神經網絡,訓練完畢后,網絡狀態處于靜止狀態,不會隨著輸入的變化而變化。
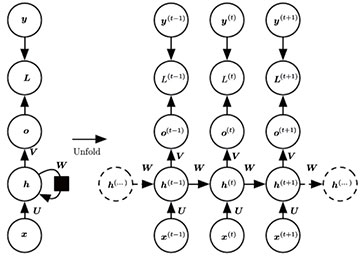
圖6遞歸神經網絡結構示意圖
除了這兩種主要的神經網絡結構外,其實還有很多各種各樣的網絡結構,如圖7[4] 所示。
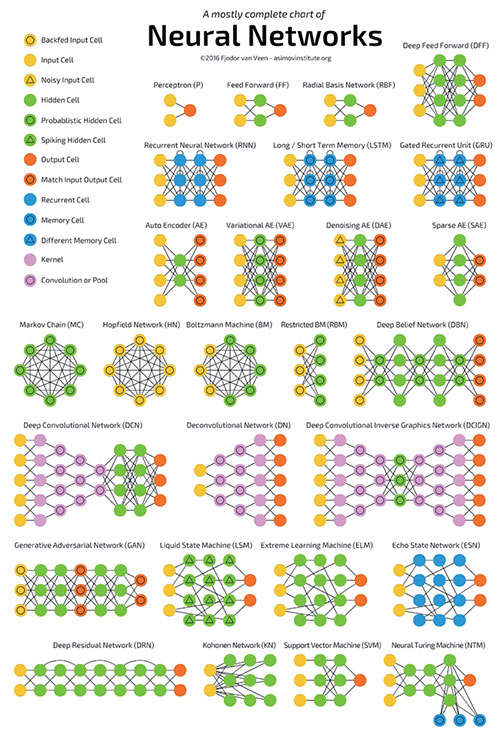
圖7神經網絡匯總[4]
神經網絡發展現狀
目前人類在腦科學方面對人腦的真正的工作機理還沒有完全弄懂。深度神經網絡,并不是嚴格意義上的類人腦計算,只是根據腦神經科學初期的研究成果,在一定程度上受到人腦信息處理機制的啟發,模擬一些人腦細胞的工作構成網絡,其本質上還是一些類似于支撐向量機、隱式馬爾科夫鏈之類的機器學習模型。比如Facebook FIR 的LeCunYann 就曾經說過,卷積神經網絡嚴格講應為卷積網絡(convolutional networks),之所以去掉“神經”二字就是為避免人們誤解。但由于歷史原因,以及一些學術論文的宣傳目的,大都冠以“神經”二字,但目前在人類還未完全弄懂人腦全部工作機理的前提下,是不可能構造真正類似人腦一樣的神經網絡。
深度神經網絡相比傳統方法具有更強的特征表達能力,但它并不是萬能的,也并不是適用于所有的問題。同時深度神經網絡訓練需要數據量足夠大,若數據量不夠大會導致過擬合,神經網絡的優勢就體現不出來。
但是在一些方面,深度神經網絡確實有比人腦有更強大的地方,比如深度神經網絡可以具有海量的內存存儲能力,輕松把人腦無法記憶的許多數據存儲起來進行檢索。目前情況是,使用一個類型的數據集訓練得到的深度神經網絡不能對其他類型的數據進行應用,神經網絡的功能單一,還無法跨領域學習;但是人腦可以在不同應用領域輕松的實現跨域聯想,可以在數學領域借鑒音樂美術等藝術領域的一些思想火花。在圍棋戰勝李世石的AlphaGo 并不會下簡單的象棋或者軍棋,但是人腦可以輕松的進行類似思維切換。所以近期google 的Raia Hadsell 團隊使用連接的神經網絡結構實驗這種可以實現思維切換的通用人工智能(general artificialintelligence):進步神經網絡(progressiveneural networks)[5],就是想打破這種功能限制,在神經網絡的通用性上進行探索。如圖8 所示,一個三列進步神經網絡示意圖,左邊的兩列(虛箭頭)分別在任務1 和任務2 上進行訓練,標a 的灰色框表示適應層(adapterlayers),附加上右邊的第三列用于任務3,可以訪問前面已經學習到的所有特征。
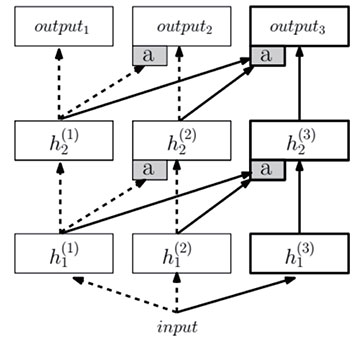
圖8 進步神經網絡
探索道路上人類才邁出了一小步,到底什么時候會真正探索到真理不得而知。如LeCunYann 就曾指出,現在大量使用的深度學習模型都是使用監督學習的方式,但是人腦的學習方式是無監督的。學者們在無監督學習的探索才剛剛開始。
雖然神經網絡還處于發展初期,但表現出的超強能力,尤其自動駕駛、輔助駕駛方面的能力在全球各地有大量的實驗以及應用。
比如最近美國國家交通部就正式發布針對自動駕駛汽車(self-driving cars/ automatedvehicles)的征求意見稿,美國前總統奧巴馬還專門發表講話[6] 把自動駕駛作為高新產業在美國的快速規范發展。自動駕駛汽車類似于機器人,集成了大多數的人工智能技術,自動駕駛技術的發展會極大促進整個人工智能技術的發展。
由于媒體和人工智能廠商的肆意夸大宣傳,導致非專業人們對深度神經網絡產生很多誤解,甚至引起恐慌,這些都是完全沒有必要的。比如2016 年9 月,特斯拉在中國的一次車禍中,23 歲駕駛者駕駛一輛Model S 撞向路中間的道路清掃車致死。死者父親接受采訪時表示[7],他兒子一直信賴自動駕駛,因此在事故發生時并沒有在觀察路面情況。事故發生后,特斯拉在其中文網站中去掉了“自動駕駛”這個詞。同時特斯拉表示,自動駕駛系統不是為了徹底取代駕駛員,打開自動駕駛后,駕駛員會受到語音和文字告警,迫使駕駛員將雙手放在方向盤上,并注意路面情況。
但是某些媒體把這種需要駕駛員協助的自動駕駛吹噓成無人駕駛,這極大誤解了人工智能技術,對技術的發展以及產業的發展都不會有好處,當達不到宣傳的預期效果時,反而會給消費者產生不信任的印象。
目前已經應用或者打算應用的自動駕駛汽車案例(優步攜手沃爾沃將在美國匹茲堡提供無人駕駛叫車服務,以及新創公司NuTonomy 的無人自駕計程車在新加坡緯壹科技城商業區投入運營)都必須在限制的場景。目前來看,還無法實現能夠在各種場景中的真正的自動駕駛,人工智能在某些領域很難達到人類水平的智能。
神經網絡在安防行業中的應用現狀
自從2012年AlexNet 發布后,和人工智能相關的眾多學科的研究人員把深度神經網絡用于自己的研究領域,都取得了豐碩成果。安防行業主要與圖像視頻應用相關,其中最主要的研究方向有:圖片或視頻中的對象檢測(object detection)、圖片或視頻中的對象定位(object localization)、基于視頻的目標跟蹤(object tracking)、基于圖片或視頻場景分類(scene classification)、基于圖片或視頻的場景解析(scene parsing)、基于圖片或視頻的目標行為識別(activityrecognition)。用于圖像分類和檢測應用的深度神經網絡,AlexNet 后又出現了牛津大學的VGGNet,谷歌的GooLeNe(t Inception-v1、Inception-v2、Inception-v3、Inception-v4)以及后微軟的ResNet(Resnet1、Resnet2),還有這兩種結構結合后形成的Inception-ResNet、Inception-ResNet-v2。短短4年時間里,學術研究在積極探索著引領著網絡結構的快速發展,同時產業界也積極把學術界的研究成果引入的各自的產品當中,并且結合產品應用的實際場景,對網絡模型進行優化和增量訓練,取得了卓越的效果。比如宇視科技的智能識別服務器IA8500-FA和IA9600-FS,視頻摘要和視頻濃縮服務器IA8500-VI、IA8800-VI、IA8800-VIM,都已經使用NVIDIA 公司新款GPU,同時配置卓越的深度神經網絡結構,在各項檢測和識別指標上在業界都達到了優秀水平。
在安防行業的分布式計算以及大數據挖掘方面,將來也會涌現出大量的創新與應用。對深度神經網絡應用來說,網絡結構與模型、實現代碼已經變得不再重要。不同于傳輸的智能算法開發,單憑一家力量很難取得優異的結果。海量數據或者說大數據變得比網絡結構和代碼變得更重要!同時必須借助開源力量共同推進發展。所以在業界,尤其是學術以及行業領導者(google、facebook FAIR、美國紐約大學LeCunYann 團隊、加拿大蒙特利爾大學Geoffrey E. Hinton 團隊、百度的前吳恩達團隊),紛紛開源自己的各種項目的代碼,借助同行業的力量推動發展,同時建立在領域內的領導地位。
人工智能在安防行業應用展望
在安防行業,目前人工智能算法使用最多的還是在視頻圖像領域,因為傳統的安防企業的產品都是與視頻圖像相關。但對于有些業務應用來說,視頻圖像只是一小部分,還需要網絡信息、通信信息、社交信息,等等。將來安防行業還需要以視頻圖像信息為基礎,打通各種異構信息,在海量異構信息的基礎上,充分發揮機器學習、數據分析與挖掘等各種人工智能算法的優勢,為安防行業創造更多價值。
參考文獻
[1]https://en.wikipedia.org/wiki/Artificial_intelligence
[2]http://papers.nips.cc/paper/4824-imagenet-classification-with-deepconvolutional-neural-networks
[3]http://www.deeplearningbook.org/
[4]http://www.asimovinstitute.org/neural-network-zoo/
[5]http://arxiv.org/abs/1606.04671
[6]http://www.post-gazette.com/opinion/Op-Ed/2016/09/19/Barack-Obama-Self-driving-yes-but-also-safe/stories/201609200027
[7]http://m.cn.nytimes.com/technology/20160918/fatal-tesla-crash-in-china-involved-autopilotgovernment-tv-says/
 浙公網安備
33010802004032號
浙公網安備
33010802004032號

